The argument against Entity Framework, and for micro-ORMs.
posted on Sep 22, 2019
Preface
I've worked with Entity Framework (since the .NET 3.5 days, both code-first and database-first) as well as the latest .NET Core version. It was my preferred solution for a while and I've gotten pretty good with it. Looking back, I regret having to learn the hard way that EF is very taxing and it just isn't a good choice for most solutions.
There are many ORMs in the .NET world, but I think my point could be made when picking one of each a fully-fledged ORM, and a micro ORM.
- Full ORM - Entity Framework Core - Chosen because it is the unofficial official version for .NET. It is front-and-center in most of the "Getting Started" docs and is what most junior devs will choose when beginning their journey into .NET.
- Micro ORM - ServiceStack.OrmLite - For the sake of argument, I could easily have chosen other solutions, such as Dapper or PetaPoco, but I'm a fan of the API/features that ServiceStack.OrmLite provides. NOTE: OrmLite is free for open-source, but paid for closed-source.
Surface area/exposure
As with picking any dependency on your project, you must step back and take a 20,000-foot view of things to determine its impact on your solution. One way to do this is to consider the size of the dependency via the lines-of-code.
Using cloc, here is the overview of the size of each codebase.
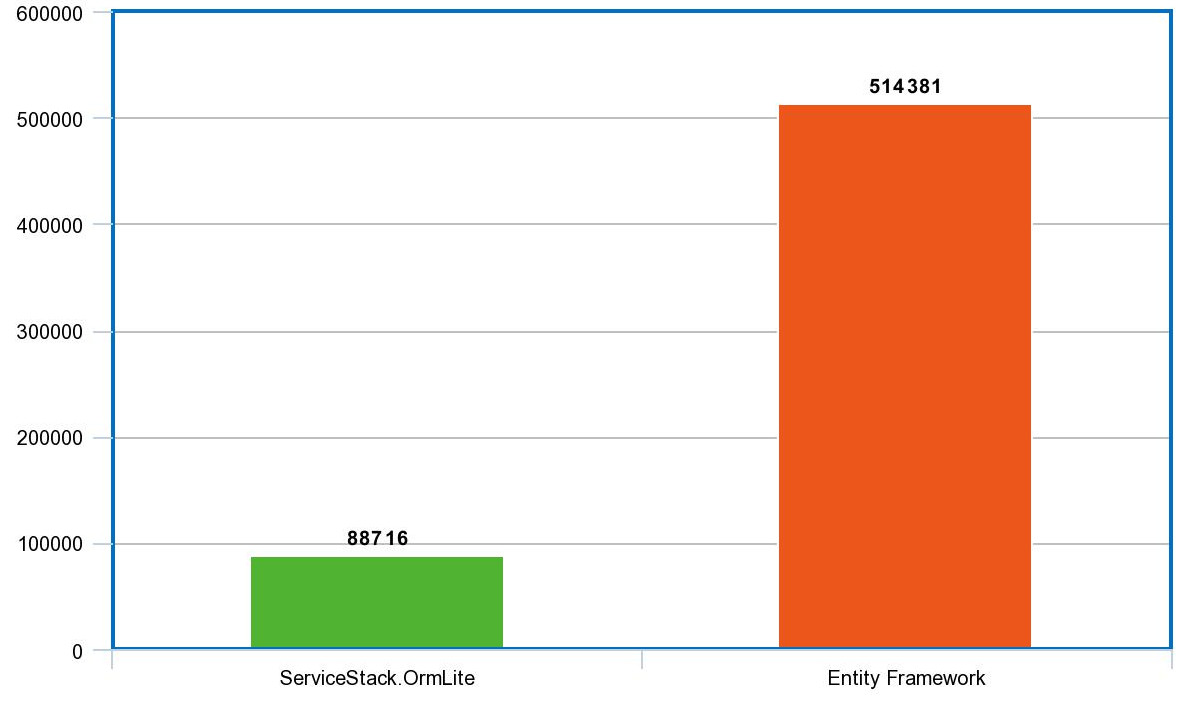
Purely considering lines-of-code can be a fool's errand, but there is more to the story here. As the saying goes "more money, more problems", right? As you increase your surface area (including your dependency graph), you increase your chances of running into bugs/issues. As you sit on top of more layers of abstraction and indirection, the problems that you begin to run into begin to get more cryptic and harder to isolate/fix.
You can get a sense of this by spending a few minutes on the issue pages for each ORM (here and here). You'll find that the issues in OrmLite are generally about the problem-domain (getting data in-and-out of the database) or the underlying ADO provider, whereas the issues in EF generally involve the layers/types that are involved in the abstractions.
When it comes to the scope of your dependency and the exposure it brings to your project, I wouldn't take this point lightly. It is often overlooked, and when it does eventually tax your solution, it can go unnoticed/unrealized.
You can't escape the issues of just "getting data in and out" and the underlying database. However, there is a huge swath of issues that can be completely avoided by just choosing not to expose yourself. Smaller targets are harder to hit. Keep your dependencies small.
Bare metal
Micro ORMS are usually just extensions on top of raw ADO types (IDbCommand, IDbConnection, etc) and OrmLite is no exception. These extensions usually go only so far as to prevent the user from having to manually manage SQL strings, which is an obvious maintenance nightmare.
At this point of abstraction, no real complaints can be made. You get fully type-checked access to your underlying database, with a 1-to-1 relationship between your types and the data they represent. Your data types (POCOs) are expressed clearly. No magic. No voodoo. No "secret" tables for mapping many-to-many relationships. No complex graph management. No virtual proxies and lazy collections. No navigation properties leaked. These things usually end up just adding friction to your project, caking on additional features that silently tax you.
If exceptions happen when using OrmLite (or micro ORMs), they are usually a result of the underlying ADO provider, key constraints, etc. It's better to be closer to the metal when an issue arises because the cause/fix is usually more clear.
A common misconception is that "because you're bare metal, you need more boilerplate!" This just isn't true. I mean, in the case of working with HTTP over a raw TCP connection, of course. You'd want a higher-level abstraction. But this just isn't the case with OrmLite (or Micro ORMs in general). I'd wager that I'd get by with fewer lines of code when using OrmLite over EF.
Let's say you have a business requirement of storing/retrieving data. You've ruled out the need for non-conventional databases (graph, Cassandra, etc) and have decided that a relational database will work. The following code illustrates the bare minimum needed to tackle your problem, using OrmLite.
class Program
{
public class Person
{
[AutoIncrement]
public int Id { get; set; }
public string Name { get; set; }
}
public static void Main(string[] _)
{
var factory = new OrmLiteConnectionFactory(":memory:", SqliteDialect.Provider);
using (var db = factory.OpenDbConnection())
{
db.CreateTable<Person>();
var person = new Person { Name = "Paul" };
var personId = db.Save(person); // Id is also auto set.
using (var trans = db.OpenTransaction(IsolationLevel.ReadCommitted))
{
person = db.Single(db.From<Person>().Where(x => x.Name == "Paul"));
person = db.SingleById<Person>(personId);
person.Name = "Another name";
db.Save(person);
trans.Commit();
}
}
}
}Any business requirement can be achieved with the above code. There is little in the way to prevent you from defining your solution/architecture how you'd like. OrmLite (micro ORMs) focus on exactly what is needed to solve your problem. Nothing more, nothing less. This brings me to my next point.
Heavy ORMs impose artificial abstractions that force you into a unique style of development that's introducing a further disconnect and layer of indirection between your code and your database, requiring the usage the usage of augmented and proxied EF-specific models. Using this abstraction isn't going to make you a better OOP of FP programmer or make you more knowledable about SQL or any RDBMS-specific features.
Sitting on EF's layers limits your ability to clearly perdict the behavior and functionality of each query, instead relying on EF-specific behavior. This makes it harder to reason about your code as you'll need to keep a hidden context of the incidental complexity in EF's behavior when reviewing code. You'd have to know exactly EF does, when it does it and why it does it when diagnosting unwanted behavior like unintended data access.
Missing features
I believe I've set a high bar up until this point when it comes to choosing EF over OrmLite, but this doesn't factor the additional features that developers have come to love with EF.
- Migrations
- Change tracking
- Unit of work
- Lazy collections
- Navigation properties (joins and projections)
- Result caching
- Graph persistence
- ...the list goes on
In my opinion, each of these features is unlikely to address a business concern directly. However, they are still typically highly valued by developers for various reasons.
These features must each be carefully considered. Even if you won't use/benefit from a feature, there is still a cost with having it exist at all. They typically only exist in heavy ORMs (EF) found in enterprise languages (Java/.NET).
I'd prefer to code againt clean APIs that lerverage the DB's underlying functionality and features.
With that said, let me try to address a few of these features.
Migrations
Migrations are a requirement of just about every solution. A few things to consider.
First, just because you didn't write the code, doesn't mean someone didn't write the code. Choosing a batteries-included approach doesn't make your solution any simpler. You can put the engine under the hood, or in the trunk, but it will still break down.
Secondly, choosing a batteries-included approach for a one-size-fits-all solution often means that there are additional edge cases for use-cases that just don't apply to you. This may seem irrelevant, but even if you are using 20% of the feature, that doesn't mean you aren't sitting the abstractions needed specifically needed for the other 80% you don't need.
Lastly, what happens when something goes wrong? Things are a lot easier to debug/fix when you own the solution and there isn't any white noise. What happens when you run into an issue like this? What about the time spent debugging? Or fixing a database that the migration failed on? At that point, you've already spent more time using a feature that you didn't implement than it would have taken to just implement migrations yourself.
Seriously, write your own migration layer. I wrote this in 3 minutes.
class Program
{
public interface IMigration
{
void Run(IDbConnection connection);
int Version { get; }
}
public class Migrator
{
private readonly OrmLiteConnectionFactory _connectionFactory;
private readonly IList<IMigration> _migrations;
public Migrator(OrmLiteConnectionFactory connectionFactory, IList<IMigration> migrations)
{
_connectionFactory = connectionFactory;
_migrations = migrations;
}
public void Migrate()
{
using (var connection = _connectionFactory.OpenDbConnection())
{
connection.CreateTableIfNotExists<Migration>();
var installedMigrations = connection.Select<Migration>();
using (var transaction = connection.BeginTransaction())
{
foreach (var migration in _migrations.OrderBy(x => x.Version))
{
if (installedMigrations.Any(x => x.Version == migration.Version))
{
// Already done!
continue;
}
migration.Run(connection);
connection.Insert(new Migration
{Version = migration.Version, AppliedOn = DateTimeOffset.UtcNow});
}
transaction.Commit();
}
}
}
public class Migration
{
[AutoIncrement]
public int Id { get; set; }
public int Version { get; set; }
public DateTimeOffset AppliedOn { get; set; }
}
}
public class TestMigration1 : IMigration
{
public void Run(IDbConnection connection)
{
// Raw and auditable SQL.
// Create tables, add/drop columns, etc.
}
public int Version => 1;
}
public class TestMigration2 : IMigration
{
public void Run(IDbConnection connection)
{
// Raw and auditable SQL.
// Create tables, add/drop columns, etc.
}
public int Version => 2;
}
public static void Main(string[] _)
{
var factory = new OrmLiteConnectionFactory(":memory:", SqliteDialect.Provider);
var migrator = new Migrator(factory, new List<IMigration>
{
new TestMigration1(),
new TestMigration2()
});
migrator.Migrate();
}
}With less than 100 lines of code, you now have a solution that will have near-zero issues. And if there happens to be an issue, there is a good chance that any developer could fix it within minutes. There is no learning curve. No documentation to read. No CLIs to invoke. No hidden tax bill that will paid in the future.
Change tracking
@ardave2002: I find having a giant ball of mutable state with change detection via virtual proxy that spans my application from one edge to the other to provide huge benefits to my ability to reason about code </s>
In my opinion, this feature is just annoying. There is a performance overhead that you introduce when using this feature. This causes you to leak concerns into your application layer, adding AsNoTracking() on all of your read-only queries. Also, having ambient state in your application is generally a bad idea. There are risks associated with having the semantics of SaveChanges() differ depending upon factors that are outside scope. It makes things very difficult to reason with at first glance.
Unit of work
I have a hard time discussing this feature because people sometimes conflate this pattern with simple transactions, which exist in raw ADO. You will only have issues if you intend to use TransactionScope from EF, which is a little more than a simple transaction. If you don't intend on using this class, then this isn't a missing feature when choosing OrmLite over EF.
But if you need TransactionScope-like behavior, there are multiple ways in which this could be done. First, you could invert the creation of these objects so that implicitly shared/scoped instances can be used for every request. I've also used AsyncLocal successfully to use cached instances of IDbConnection and IDbTransaction for every nested method call. This is something that could be hand-rolled with minimal lines of code, similarly to the migration approach above.
But in the end, this only matters if you intend to use TransactionScope. Otherwise, this isn't a feature you're missing.
Lazy collections
This is a feature that can seem appealing at first but can be very problematic. Do you want database queries to happen implicitly in your views? This is compounded when you are enumerating a collection of objects that have nested lazy properties, causing an additional database query for each for loop.
This is just a really bad idea. Define your query model upfront and fully load it to avoid unintended side effects that only show themselves when unbounded collections inevitably grow.
Misc
What happens when things just are performant with EF? It's great that it allows you to analyze the SQL being executed, but at that point, you are still at the mercy of the underlying SQL generation. You may decide to jump out of EF in these cases and just execute raw SQL, but why even subject yourself to this?
I also don't like hearing the caveats of "if you know how to use it" or "when used right" when describing features of EF. I'm uncomfortable with the idea of playing hot potato with loaded guns, hoping every person catches the gun just right. Not everyone is as knowledgeable as you. Code reviews are a good thing, but depending upon them isn't a good idea. Things get past code reviews. All developers suck, including me and you. Why even risk it?
Final words
An ORM should only serve to give you a type-safe approach to writing SQL. Anything else is a tax that gets compounded as your project evolves.
You could use EF and everything turns out just fine, but the standard deviation between success and failure is wide. When you choose a micro ORM, that standard deviation is much smaller.
Quite frankly, you'd be hard-pressed to ever find a business requirement that only EF could solve. The features that EF provides and OrmLite doesn't are welcomed by developers as being time-saving nice-to-haves. However, when you factor in the taxing nature of using such a large framework like EF, you'll spend more time using it than if you were to just keep things minimal and bare-metal. This is especially true for larger projects involving people with ranging experiences.
If you'd like to add anything, please comment. I love the discussion.
Update: I created SharpDataAccess. It is a thin layer that sits on top of ServiceStack.OrmLite that adds migrations and ambient connections/transactions.
Comments
There are no comments yet.